
For the code and instructions on how to run, Please Visit :
https://github.com/kr1210/Human-Pose-Compare
Pose Estimation is one of the more elegant applications of neural networks and is startlingly accurate and sometimes, seems like something right out of science fiction.
For Instance, check out Google’s Move Mirror, an in-browser application that estimates the user’s pose in real time and then displays a movie still with the actor holding the same pose.
When I glanced over it, however, I got an idea. What if the same methodology could be used to compare the same actions performed by two people? This technology could then be used to teach people over remote view! I got to work immediately and tried to reverse engineer the techniques used by Google.
I found, to my disappointment, a few Tensorflow.js tutorials and theories on the same and nothing in python. This was understandable as it was an in-browser application and so, I decided to port the code to mighty Python.A few sessions of research showed me that they were using Posenet, a fast yet accurate model, for estimating pose. Then there were a few under-the-hood operations in order to assist the model,which we’ll go into detail in a bit.
The Objective was simple: I wanted to go one step ahead and compare a whole action such as a punch or a kick with an image and tell me the extend to which it was correct.
Now let’s take a look at all the steps that were taken
- The Model: As I stated earlier, Google Mirror uses PoseNet, a deep learning model which specifies 17 points on the human body. I found a good python implementation of it here.
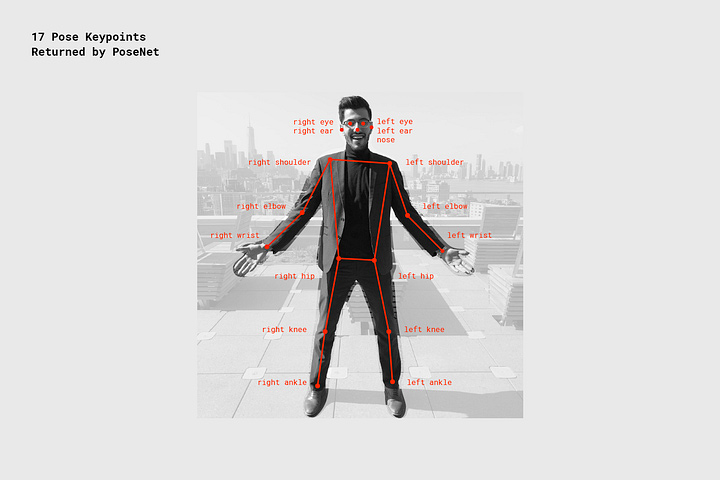
The next challenge was defining similarity. When we think about the problem,we see that there are many uncertainties to be addressed: humans can have different heights and body shapes, they might be in different parts in the picture: one person may have been standing close to the camera, another might have been faraway. All these problems have to be solved in order to output a correct result. I decided to take all the steps followed by Google.
- A new Bounding box : From the model output, we get the co-ordinates of the 17 key-points on a person’s body. This information can be used to create a new bounding box which tightly covers the person in the picture.This solves the problem of people appearing in different parts of the picture.
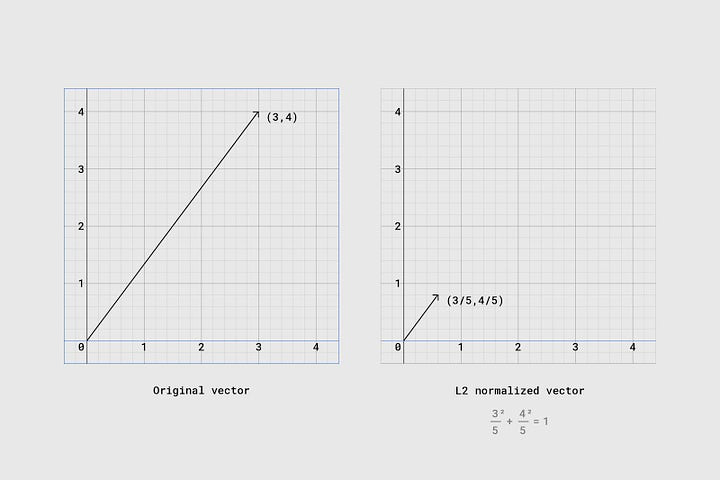
- Normalization of the points: In order to account for the size inconsistencies, we perform L2 normalization of the points in order to transform it into a unit vector. The defining property of an L2 normalized vector is that the sum of the squares will be equal to 1.
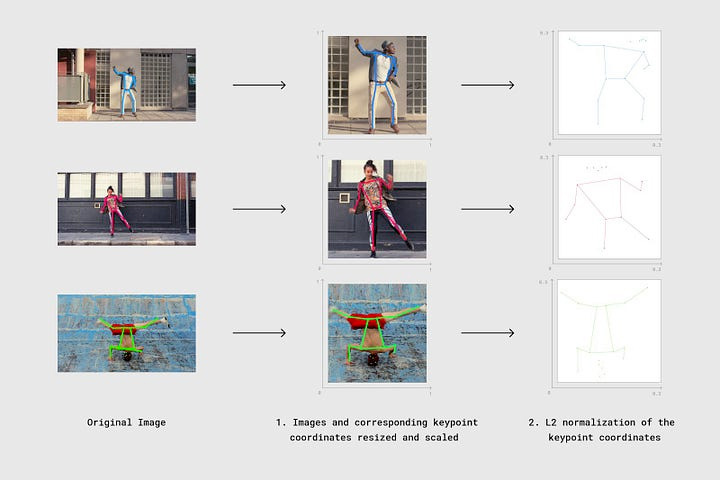
Now that we have standardized the pose vectors, it is time to choose a similarity measure. I chose cosine similarity for this particular instance, mainly because we are working with vectors.
Cosine Similarity
Cosine similarity of two vectors are defined as follows:
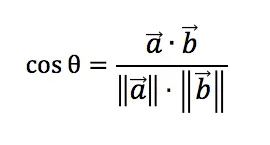
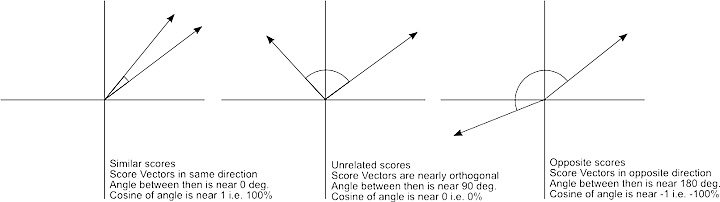
The 17 key-points are converted into a vector and plotted in high dimensional space. This vector plotting is compared to another vector plot from our benchmark image.
The direction of vectors here are an indication of the similarity of the poses. Vectors going in similar directions are similar, while those going at fairly different or opposite directions are different.
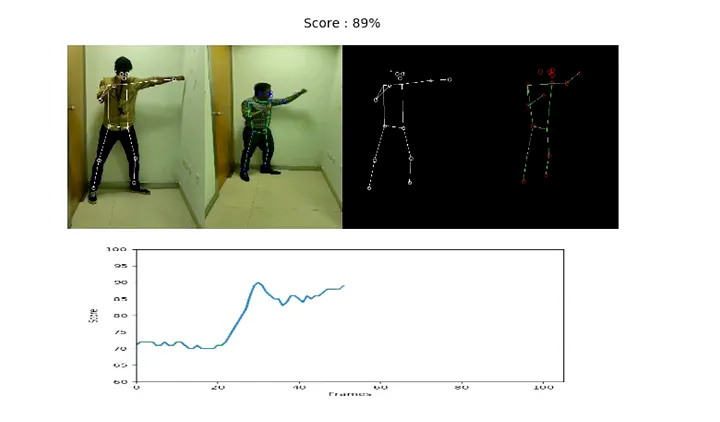
Now, given our earlier video of a man doing a punch, I simply estimated the pose for each frame and standardized the vectors and stored them in an array.I already had a pickle file saved which contained the normalized vector for the pose of a perfect punch. Now, all I had to do was compute the cosine similarity between both at each frame and take the average of all the scores.
We can see that there is a peak where the person performing the action mimics the pose of the person in the picture. It seems I succeeded to an extent.
But the drawbacks are evident:
- The algorithm does not take into account the time taken to perform the activity. This is a serious drawback if this were to be used in any training software such as martial arts etc.
- There is no scope of attaining a 100 percent score: Since the average is taken against one picture, there can never be a 100 percent score even if the person performed the action correctly.
Due to these factors, I had to conclude that this method could only be used for qualitative analysis and maybe action recognition but not as a scoring module. The temporal information had to be taken into account somehow.
Since I did not have much data to start with, any sort of deep learning methods were taken off the table right off the bat. So I began thinking of alternative methods and other vision based approaches. A quick study into this sort of problem led me to the conclusion that some sort of optical flow based methods had to be employed in order to use the temporal information in a useful manner.
From here, the method seemed very straightforward. Instead of comparing with just one image of an action, I would now be comparing the video of an action performed by a person with the video of the action performed in a correct manner – a lookup based approach, to be blunt.
But the problems seemed to be in abundance here too:
- The frames had no particular order: I simply couldn’t extrapolate the earlier method since I could not know beforehand which frames from both videos had to be compared with each other.
- The sequences could be of different lengths: Another problem which haunted me was that, even if I could somehow figure out which frames to compare with each other, the two videos need not be of the same duration.
These problems, among others, showed me that I needed to come up with an alternative method, which would take in as input the video of a person performing an action, the name of the action and a video in the lookup in which a person is performing the same action in a correct manner, and then should produce a score.
If we think carefully, this data exhibits certain describing characteristics:
- There are 17 points which are tracked by their co-ordinates
- The value of the co-ordinates change with time
These properties tell me that I can actually treat this data as a time-series and doing so, unlocks various other methods for comparison.
Dynamic Time Warping
Even though it sounds like a sci-fi method of time travel, it really isn’t. It is just a method used in comparing sequences and graphs of different lengths. It matches the different troughs and crests in a graph using one to many matching and such, resulting in synced up frames on its own.
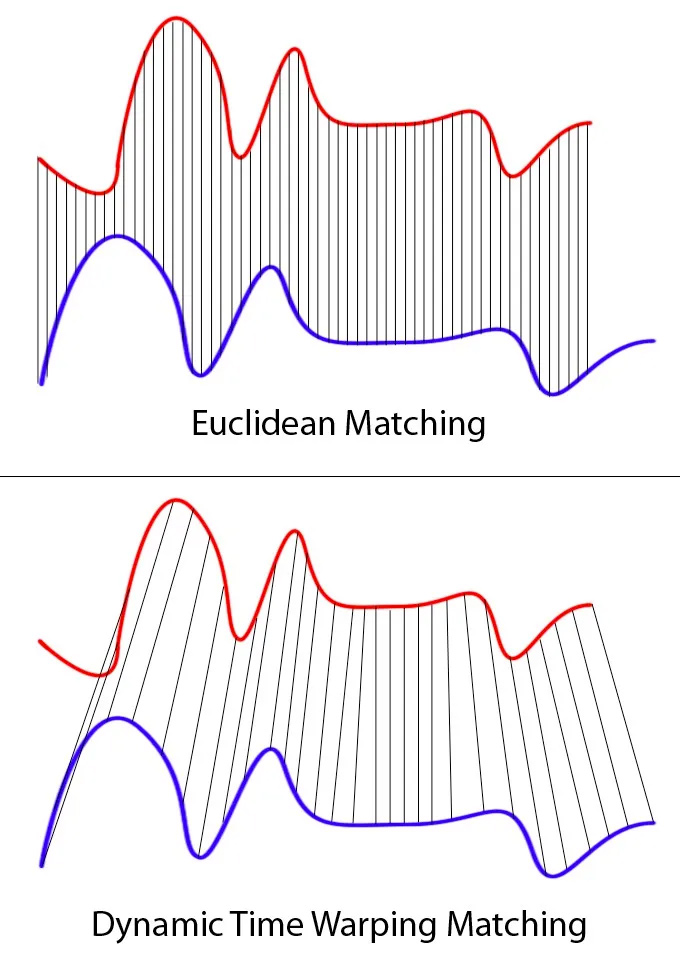
This method seemed ideal for my use case, as I had similar graphs for each of the 17 key-points as the action was performed. I could then use DTW to compare these graphs and get 17 scores for each of the 17 key-points. An average of these 17 scores could be then taken as the total score.
I used a package called dtaidistance, which was used to compute DTW scores between two sequences when given in the form of Numpy arrays.
In this way, I was able to use the temporal information gained from pose estimation at each frame in order to compare the actions performed by two people.
For example, in the case of punch, I constructed a lookup table which contained the sequence of each of the 17 keypoints for the action ‘punch’ in 3 views -front, left and right. It was stored in a dict in the following format:
{'punch - side': array([[[5.15185672e+01, 8.93372620......)
'punch - front': array([[[5.15185672e+01, 8.93372620......)
}
For the code and instructions on how to run, Please Visit : https://github.com/kr1210/Human-Pose-Compare
Improvements:
- Automation of recognition of action performed and orientation: In the code that I have showcased, the action and orientation have to be specified by the user. Instead, the first method I explained can be used to recognize the action performed and the orientation by using another lookup.
- Using confidence scores: I have not used any confidence scores returned by Posenet. These can be used to make scoring much more efficient.
- Specifying points for consideration: According to the action to be performed, specific points can be used to increase accuracy. For eg: In punching, the movement of the torso is more important than the movement of the legs.
- Providing feedback: A feedback can be given to the user as to which body part’s movement and position needs to be corrected in order to boost the scores.
References :